Python的:扩展复杂的树状数据结构数据结构、树状、复杂、Python
我正在探索其获得扩展为子元素和解析为一个最终元件的数据结构。但我只想要存储前两名的水平。
例如:可以说,我开始与纽约,打破进入布朗克斯,国王,纽约,皇后区和里士满的县,但后来终于不知何故,他们下定决心,美国
。我不知道这是否是一个很好的例子,但只是要清楚这里的问题更清楚的解释。
A(扩展到)B,C,D - >乙(扩展到)K,L,M - > ķ解析到Z
我最初写在一系列的循环,然后使用递归,但递归我失去了一些得到扩大和由于我没有深入每个扩展元素的元素。我已经把两个递归版本和非递归。我在寻找构建这个数据结构的一些建议,哪些是做的最好的方式。
我呼吁在扩大版返回项目列表的每一个元素一个数据库查询。去,直到它解析为单个元素。随着出递归我不松动钻一路,直到别人解析到最后一个元素。但随着递归的不一样。我也是新的Python,所以希望这不是一个坏的问题要问在这样的网站。
returnCategoryQuery 是通过调用数据库的查询返回的项目列表的方法。
使用了递归
#Dictionary保存最初的类别与cl_to其余
baseCategoryTree = {};
#categoryResults = [];
#查询获取所有类别一类是挂钩
categoryQuery =从categorylinks选择cl_to CL左连接页P的cl.cl_from = p.page_id其中,p.page_namespace = 14,p.page_title =;
光标= db.cursor(cursors.SSDictCursor);
关键在idTitleDictionary.iteritems()值:
对于startCategory价值[0]
#PRINT startCategory +端查询;
categoryResults = [];
尝试:
categoryRow =;
baseCategoryTree [startCategory] = [];
打印categoryQuery + startCategory +';
cursor.execute(categoryQuery + startCategory +');
做= FALSE;
而没有这样做:
categoryRow = cursor.fetchone();
如果不是categoryRow:
做=真;
继续;
categoryResults.append(categoryRow ['cl_to']);
对于subCategoryResult在categoryResults:
打印startCategory.en code(ASCII)+ - + subCategoryResult;
在returnCategoryQuery项(categoryQuery + subCategoryResult +'):
打印startCategory.en code(ASCII)+ - + subCategoryResult + - +项目;
对于子项中returnCategoryQuery(categoryQuery +项目+'):
打印startCategory.en code(ASCII)+ - + subCategoryResult + - +项目+ - +分项目;
对于subOfSubItem在returnCategoryQuery(categoryQuery +子项目+'):
打印startCategory.en code(ASCII)+ - + subCategoryResult + - +项目+ - +分项目+ - + subOfSubItem;
对于sub_1_subOfSubItem在returnCategoryQuery(categoryQuery + subOfSubItem +'):
打印startCategory.en code(ASCII)+ - + subCategoryResult + - +项目+ - +分项目+ - + subOfSubItem + - + sub_1_subOfSubItem;
对于sub_2_subOfSubItem在returnCategoryQuery(categoryQuery + sub_1_subOfSubItem +'):
打印startCategory.en code(ASCII)+ - + subCategoryResult + - +项目+ - +分项目+ - + subOfSubItem + - + sub_1_subOfSubItem + - + sub_2_subOfSubItem;
除例外,E:
traceback.print_exc();
递归
高清crawlSubCategory(subCategoryList):
级= 1;
expandedList = [];
对于eachCategory在subCategoryList:
水平=等级+ 1
打印级别+ STR(水平)++ eachCategory;
#crawlSubCategory(returnCategoryQuery(categoryQuery + eachCategory +'));
对于subOfEachCategory在returnCategoryQuery(categoryQuery + eachCategory +'):
水平=等级+ 1
打印级别+ STR(水平)++ subOfEachCategory;
expandedList.append(crawlSubCategory(returnCategoryQuery(categoryQuery + subOfEachCategory +')));
返回expandedList;
#Dictionary保存最初的类别与cl_to其余
baseCategoryTree = {};
#categoryResults = [];
#查询获取所有类别一类是挂钩
categoryQuery =从categorylinks选择cl_to CL左连接页P的cl.cl_from = p.page_id其中,p.page_namespace = 14,p.page_title =;
光标= db.cursor(cursors.SSDictCursor);
关键在idTitleDictionary.iteritems()值:
对于startCategory价值[0]
#PRINT startCategory +端查询;
categoryResults = [];
尝试:
categoryRow =;
baseCategoryTree [startCategory] = [];
打印categoryQuery + startCategory +';
cursor.execute(categoryQuery + startCategory +');
做= FALSE;
而没有这样做:
categoryRow = cursor.fetchone();
如果不是categoryRow:
做=真;
继续;
categoryResults.append(categoryRow ['cl_to']);
#crawlSubCategory(categoryResults);
除例外,E:
traceback.print_exc();
#baseCategoryTree [startCategory] .append(categoryResults);
baseCategoryTree [startCategory] .append(crawlSubCategory(categoryResults));
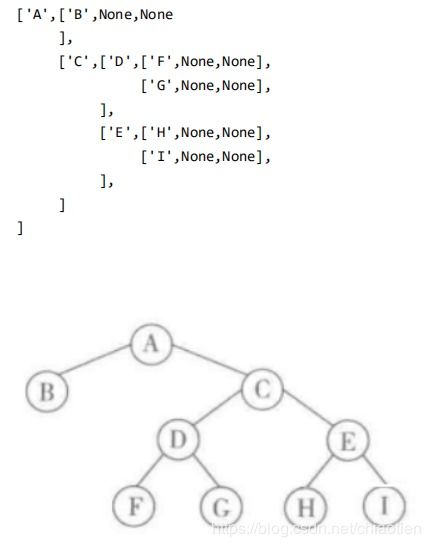
解决方案
您想查找皇后,了解它是在美国?您是否尝试过编码的树在XML中,并使用 lxml.etree 找到一个元素,然后使用 getpath 返回XPath中的格式的路径?
这将意味着增加了第四个顶层到你的树,也就是世界,然后你会搜索皇后和学习的路径,皇后是世界/美国/纽约/皇后。在回答你的问题总是在第二项的XPath 。
当然,你总是可以只建立在XML树,并用树的搜索算法。
I am exploring a data structure which get expands to sub-elements and resolves to a final element. But I only want to store top two levels.
Example: Lets say I start with New York which breaks into Bronx, Kings, New York, Queens, and Richmond as counties but then finally somehow they resolve to USA.
I am not sure if this is a good example but just to make it clear here is more clear explanation of the problem.
A (expands to) B,C,D -> B (expands to) K,L,M -> K resolves to Z
I initially wrote it in series of for loops and then use the recursion but in recursion I am loosing some of the elements that get expand and due to that I don't drill down each of the expanded element. I have put the both recursive version and non-recursive. I am looking for some advise on building this data structure, and what is the best way to do.
I call a data base query for every element in the expanded version which returns a list of items. Go until it resolves to single element. With out recursion I don't loose drilling all the way till the final element that others resolve to. But with recursion its not the same. I am also new to python so hopefully this is not a bad question to ask in a site like this.
returnCategoryQuery is a method that returns list of items by calling the database query.
With out recursion
#Dictionary to save initial category with the rest of cl_to
baseCategoryTree = {};
#categoryResults = [];
# query get all the categories a category is linked to
categoryQuery = "select cl_to from categorylinks cl left join page p on cl.cl_from = p.page_id where p.page_namespace=14 and p.page_title ='";
cursor = db.cursor(cursors.SSDictCursor);
for key, value in idTitleDictionary.iteritems():
for startCategory in value[0]:
#print startCategory + "End of Query";
categoryResults = [];
try:
categoryRow = "";
baseCategoryTree[startCategory] = [];
print categoryQuery + startCategory + "'";
cursor.execute(categoryQuery + startCategory + "'");
done = False;
while not done:
categoryRow = cursor.fetchone();
if not categoryRow:
done = True;
continue;
categoryResults.append(categoryRow['cl_to']);
for subCategoryResult in categoryResults:
print startCategory.encode('ascii') + " - " + subCategoryResult;
for item in returnCategoryQuery(categoryQuery + subCategoryResult + "'"):
print startCategory.encode('ascii') + " - " + subCategoryResult + " - " + item;
for subItem in returnCategoryQuery(categoryQuery + item + "'"):
print startCategory.encode('ascii') + " - " + subCategoryResult + " - " + item + " - " + subItem;
for subOfSubItem in returnCategoryQuery(categoryQuery + subItem + "'"):
print startCategory.encode('ascii') + " - " + subCategoryResult + " - " + item + " - " + subItem + " - " + subOfSubItem;
for sub_1_subOfSubItem in returnCategoryQuery(categoryQuery + subOfSubItem + "'"):
print startCategory.encode('ascii') + " - " + subCategoryResult + " - " + item + " - " + subItem + " - " + subOfSubItem + " - " + sub_1_subOfSubItem;
for sub_2_subOfSubItem in returnCategoryQuery(categoryQuery + sub_1_subOfSubItem + "'"):
print startCategory.encode('ascii') + " - " + subCategoryResult + " - " + item + " - " + subItem + " - " + subOfSubItem + " - " + sub_1_subOfSubItem + " - " + sub_2_subOfSubItem;
except Exception, e:
traceback.print_exc();
With Recursion
def crawlSubCategory(subCategoryList):
level = 1;
expandedList = [];
for eachCategory in subCategoryList:
level = level + 1
print "Level " + str(level) + " " + eachCategory;
#crawlSubCategory(returnCategoryQuery(categoryQuery + eachCategory + "'"));
for subOfEachCategory in returnCategoryQuery(categoryQuery + eachCategory + "'"):
level = level + 1
print "Level " + str(level) + " " + subOfEachCategory;
expandedList.append(crawlSubCategory(returnCategoryQuery(categoryQuery + subOfEachCategory + "'")));
return expandedList;
#Dictionary to save initial category with the rest of cl_to
baseCategoryTree = {};
#categoryResults = [];
# query get all the categories a category is linked to
categoryQuery = "select cl_to from categorylinks cl left join page p on cl.cl_from = p.page_id where p.page_namespace=14 and p.page_title ='";
cursor = db.cursor(cursors.SSDictCursor);
for key, value in idTitleDictionary.iteritems():
for startCategory in value[0]:
#print startCategory + "End of Query";
categoryResults = [];
try:
categoryRow = "";
baseCategoryTree[startCategory] = [];
print categoryQuery + startCategory + "'";
cursor.execute(categoryQuery + startCategory + "'");
done = False;
while not done:
categoryRow = cursor.fetchone();
if not categoryRow:
done = True;
continue;
categoryResults.append(categoryRow['cl_to']);
#crawlSubCategory(categoryResults);
except Exception, e:
traceback.print_exc();
#baseCategoryTree[startCategory].append(categoryResults);
baseCategoryTree[startCategory].append(crawlSubCategory(categoryResults));
解决方案
Are you trying to lookup "Queens" and learn that it is in the USA? Have you tried encoding your tree in XML, and using lxml.etree to find an element and then use getpath to return the path in XPath format?
This would meaning adding a fourth top level to your tree, namely World, and then you would search for Queens and learn that the path to Queens is World/USA/NewYork/Queens. The answer to your question would always be the second item in the XPath.
Of course you could always just build a tree from the XML and use a tree search algorithm.
上一篇:编写一个程序,写一个程序程序
下一篇:图中最长的路径图中、路径、最长








