如何得到csv文件的编码?文件、csv
可能重复: Accented文字不与BULK INSERT 正确导入
在我的系统上运行的.NET程序为我提供了一个CSV文件。我想知道文件的编码。
CSV文件具有电子, A , A ,æ字符,但显示为(UTF8-与BOM)。有没有办法,我可以打赌回这些字符到原来或其类似英文字符的任何可能性。
CSV文件是由.NET程序运行在相同的用户创建在同一台机器,但在创建文件后,我看不出原来的字符。
Related问题。
样本数据(UTF8-无BOM)从csv文件。
Pokmon Black版本
TGC任天堂
在Htel德RVE
拉赖因面膜等la Tour的DES Miroirs
解决方案 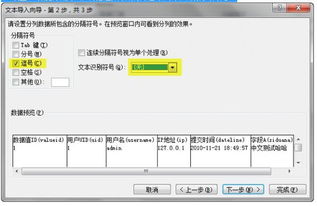
如果你看到 ,当你c中的文件为UTF-8日$ C $,但你看�,当你C时去$ C $与Windows 1252,则该文件的字面上的包含 。 I.E.它从字面上包含字节 0xEF为0xBF 0xBD (UTF-8 )。因此,该数据是不可恢复的,在这一点上。
这发生在一些字节流的物理编码来德丙它$ C $的编码不匹配。因此,例如,物理编码的Windows 1252,然后用一个程序去codeS到内部字符串使用UTF-8与更换备用。现在,该字符串内部含有 ,但它不检查,并写入到文件为UTF-8,而生成的文件就是你。
要避免原搞砸了,这是一个好主意,当解码文件,例如使用,而不是更换备用异常回退:
编码ENC = Encoding.GetEncoding(
UTF-8,
新恩coderExceptionFallback()
新德coderExceptionFallback()
);
尝试
{
File.ReadAllText(@myfile.csv,ENC);
}
赶上(德coderFallbackException E)
{
Console.WriteLine(该文件不是连接codeD的UTF-8,尝试一些其他的编码);
}
现在你会得到一个异常时,该文件不是UTF-8,你可以尝试其他的编码或者让用户知道,他的文件必须是UTF-8。
Possible Duplicate: Accented characters not correctly imported with BULK INSERT
A .net program running in my system provides me with a csv file. I would like to know the encoding of that file.
The csv file has é,ä,å,æ characters but is shown as �(UTF8-with BOM). Is there any possibility that I can bet back these characters to its original or its English like characters.
The csv file is created by a .net program running in the same machine under same user but after the creation of the file I cannot see the original characters.
Related question.
sample data (UTF8-Without BOM) from csv file.
Pok�mon Black Version
TGC � Nintendo
on H�tel de R�ve
La Reine Masqu�e et la Tour des Miroirs
解决方案
If you see �, when you decode the file as UTF-8, but you see �, when you decode it as Windows-1252, then the file literally contains �. I.E. It literally contains the bytes 0xEF 0xBF 0xBD (UTF-8 for �) . Therefore the data is unrecoverable at this point.
This happens when physical encoding of some byte stream does not match the encoding used to decode it. So for instance, the physical encoding is Windows-1252, then a program decodes it to internal string using UTF-8 with replacement fallback. Now, the string internally contains �, but it is not inspected and is written to a file as UTF-8, and the resulting file is what you have.
To avoid the original screw up, it is a good idea to use exception fallback instead of replacement fallback when decoding files, for example:
Encoding enc = Encoding.GetEncoding(
"UTF-8",
new EncoderExceptionFallback(),
new DecoderExceptionFallback()
);
try
{
File.ReadAllText(@"myfile.csv", enc);
}
catch (DecoderFallbackException e)
{
Console.WriteLine("This file was not encoded in UTF-8, try some other encoding");
}
Now you get an exception when the file isn't UTF-8 and you can either try other encoding or let the user know that his file must be in UTF-8.









