堆排序伪code算法算法、code
在堆排序算法
N = M
对于k:= M DIV 2下降到0
downheap(k)的;
重复
T:= A [0]
一个[0]:=一个[N-1]
一个[N-1]:=吨
N-
downheap(0);
直到N'LT; = 0
可不可以有人请向我解释什么是行完成
N = M
对于k:= M DIV 2下降到0
downheap(k)的;
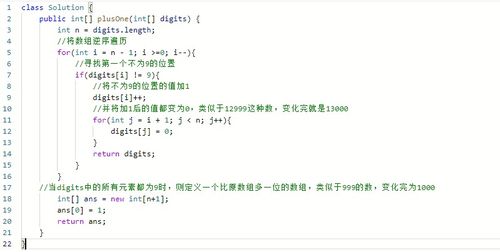
我认为这是堆建设过程中,但什么是均值的对于k:= M DIV 2下降到0
另外是n在重新presentation阵列items.So的数目最后一个元素被存储在[N-1]? 但是,为什么对n做> = 0,我们不能完成> 0.Because的第一个元素被自动排序?
解决方案 N = M
对于k:= M DIV 2下降到0
downheap(k)的;
在二元堆,一半节点都没有孩子。所以,你可以在开始的中点,并筛选项下建立一个堆。你在做什么这里是建设从下往上堆。考虑5个项目数组:
[5,3,2,4,1]
或者,就像一棵树:
5
3 2
4 1
长度为5,所以我们要开始在索引2(假设从1开始的堆阵列)。 downheap ,然后,将着眼于 3 标记的节点,并将其与最小的孩子比较。自1998年1小于3时,我们交换给项目:
5
1 2
4 3
由于我们到达叶级,我们正在与该项目完成。继续前进到第一个项目, 5 。它比 1 较小,所以我们交换物品:
1
5 2
4 3
不过,该项目 5 仍比其子大,所以我们做的另外一个交换:
1
3 2
4 5
和我们就大功告成了。你有一个有效的堆。
这是有益的做到这一点的手(用铅笔和纸),以建立一个更大的堆 - 说的10个项目。这会给你的算法如何工作的一个很好的理解。
为了构建堆以这种方式,它并不重要,如果数组索引为0或1开始。如果数组是基于0的,那么你最终使一个额外调用 downheap ,但是,这并不做任何事情,因为你试图向下移动节点已经是叶节点。因此,它是稍微低效(一个额外调用 downheap ),但不会对人体有害。
这是很重要的,但是,如果你的根节点的索引为1,您使用停止你的循环N'GT; 0 ,而不是 N'GT; = 0 。在后一种情况下,你很可能最终会加入一个假的价值,你堆和移除应该是有一个项目。
In heap sort algorithm
n=m
for k:= m div 2 down to 0
downheap(k);
repeat
t:=a[0]
a[0]:=a[n-1]
a[n-1]:=t
n—
downheap(0);
until n <= 0
Can some one please explain to me what is done in lines
n=m
for k:= m div 2 down to 0
downheap(k);
I think that is the heap building process but what is mean by for k:= m div 2 down to 0
Also is n the number of items.So in an array representation last element is stored at a[n-1]? But why do it for n> = 0. Can't we finish at n>0.Because the first element gets automatically sorted?
解决方案n=m
for k:= m div 2 down to 0
downheap(k);
In a binary heap, half of the nodes have no children. So you can build a heap by starting at the midpoint and sifting items down. What you're doing here is building the heap from the bottom up. Consider this array of five items:
[5, 3, 2, 4, 1]
Or, as a tree:
5
3 2
4 1
The length is 5, so we want to start at index 2 (assume a 1-based heap array). downheap, then, will look at the node labeled 3 and compare it with the smallest child. Since 1 is smaller than 3, we swap the items giving:
5
1 2
4 3
Since we reached a leaf level, we're done with that item. Move on to the first item, 5. It's smaller than 1, so we swap items:
1
5 2
4 3
But the item 5 is still larger than its children, so we do another swap:
1
3 2
4 5
And we're done. You have a valid heap.
It's instructive to do that by hand (with pencil and paper) to build a larger heap--say 10 items. That will give you a very good understanding of how the algorithm works.
For purposes of building the heap in this way, it doesn't matter if the array indexes start at 0 or 1. If the array is 0-based, then you end up making one extra call to downheap, but that doesn't do anything because the node you're trying to move down is already a leaf node. So it's slightly inefficient (one extra call to downheap), but not harmful.
It is important, however, that if your root node is at index 1, that you stop your loop with n > 0 rather than n >= 0. In the latter case, you could very well end up adding a bogus value to your heap and removing an item that's supposed to be there.










