就是这唯一的字符串函数的执行时间减少了从天真的为O(n ^ 2)方法?执行时间、字符串、函数、天真
通用算法来推断,如果一个字符串包含所有唯一的字符(包括不使用任何其他数据结构)表示,要经过串,迭代对整个字符串每个字母搜索匹配。这种方法的为O(n ^ 2)的。
下面的方法(用C语言编写)使用用于迭代多弦形部分偏移,由于例如在一个短字符串没有理由与第一字符测试的最后一个字符的第一个字符已经这样做。
我的问题是:是否该算法的运行时间,然后的 O(N!)的或类似的 O(nlogn)的
的#include< stdio.h中>
INT strunique(为const char *海峡)
{
为size_t偏移量= 1;
字符*球探=(字符*)海峡,*启动;
对于(*球探='\ 0';!++侦察,+偏移)
对于(开始=(字符*)STR +偏移; *开始='\ 0';!++开始)
如果(*开始== *侦察兵)
返回0;
返回1;
}
INT主要(无效)
{
的printf(%D \ N,strunique(uniq的));
的printf(%D \ N,strunique(repatee));
返回0;
}
解决方案
没有,它仍然为O(n ^ 2)。你只要稍微提高了不变。你还是得把两个loops-基本天真计数测量大O时间应该告诉你的循环方式。
此外,有没有这样的事情为O(n + 1 / 2N)。大O符号是给你的大小事情的顺序应采取的想法。 N + 1 / 2N = 1.5N。由于大O子站所有不变的因素,那也只是为n。
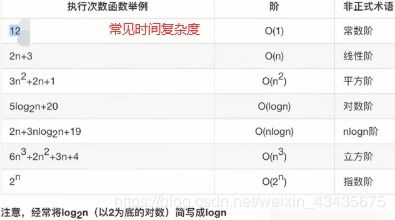
您可以击败为O(n ^ 2),无需额外的内存,但。如果不出意外,你可以通过ASCII码值(n日志(n)的时间)对字符串进行排序,然后步行数组,寻找受骗者(n次)为O(N + nlogn)= O(nlogn)的时间。有可能是其他的技巧,以及。
请注意,所述分类方法可能不提供更好的运行时though-用简单的方式具有1的最好的情况下运行时,而排序第一算法来排序,因此它具有nlogn的最佳情况。所以最好的大O时间可能不是最好的选择。
The generic algorithm to deduce if a string contains all unique characters (and that does not use any other data structures) says to go through the string, iterating each letter against the entire string searching for a match. This approach is O(n^2).
The approach below (written in C) uses an offset for the iterating over the string part, since for example in a short string there is no reason to test the last character with the first character as the first character already did that.
My question is this: Is the runtime of the algorithm then O(n!) or something like O(nlogn)?
#include <stdio.h>
int strunique(const char *str)
{
size_t offset = 1;
char *scout = (char *)str, *start;
for (; *scout != '\0'; ++scout, ++offset)
for (start = (char *)str + offset; *start != '\0'; ++start)
if (*start == *scout)
return 0;
return 1;
}
int main(void)
{
printf("%d\n", strunique("uniq"));
printf("%d\n", strunique("repatee"));
return 0;
}
解决方案
No, it's still O(n^2). You just slightly improved the constant. You still have to make two loops- basically the naive count the loops way of measuring big O time should tell you this.
Also, there is no such thing as O(n+1/2n). Big O notation is to give you an idea of the order of magnitude something should take. n+1/2n= 1.5n. Since big O drops all constant factors, that would just be n.
You can beat O(n^2) without extra memory though. If nothing else you can sort the strings by ascii value (nlog(n) time) and then walk the array looking for dupes (n time) for O(n+nlogn)=O(nlogn) time. There's probably other tricks as well.
Note that the sorting approach may not give better runtime though- the naive way has a best case runtime of 1, while a sort first algorithm has to sort, so it has a best case of nlogn. So best big-O time may not be the best choice.









