我如何计算两个重叠的线性数据集之间的地步?线性、地步、两个、数据
予有两组重叠数据位(见下面的图)。我需要找到这些集之间的地步,谁也想不到一个未知的数据点都属于特定类别。
如果我有一个新的数据点(假设 5000 ),并有赌的 $$$ 它是否属于A组或B组,我怎么能计算,使我的投注最有把握的地步?
请参阅样本数据集,并伴随着以下情节与这些团体之间的近似点(用眼睛来计算)。
A组
[385,515,975,1136,2394,2436,4051,4399,4484,4768,4768,4849,4856,4954,5020,5020,5020,5020,5020,5020,5020,5020,5020,5052,5163,5200,5271,5421,5421,5442,5746,5765,5903,5992,5992,6046,6122,6205,6208,6239,6310,6360,6416,6512,6536,6543,6581,6609,6696,6699,6752,6796,6806,6855,6859,6886,6906,6911,6923,6953,7016,7072,7086,7089,7110,7232,7278,7293,7304,7309,7348,7367,7378,7380,7419,7453,7454,7492,7506,7549,7563,7721,7723,7731,7745,7750,7751,7783,7791,7813,7813,7814,7818,7833,7863,7875,7886,7887,7902,7907,7935,7942,7942,7948,7973,7995,8002,8013,8013,8015,8024,8025,8030,8038,8041,8050,8056,8060,8064,8071,8081,8082,8085,8093,8124,8139,8142,8167,8179,8204,8214,8223,8225,8247,8248,8253,8258,8264,8265,8265,8269,8277,8278,8289,8300,8312,8314,8323,8328,8334,8363,8369,8390,8397,8399,8399,8401,8436,8442,8456,8457,8471,8474,8483,8503,8511,8516,8533,8560,8571,8575,8583,8592,8593,8626,8635,8635,8644,8659,8685,8695,8695,8702,8714,8715,8717,8729,8732,8740,8743,8750,8756,8772,8772,8778,8797,8828,8840,8840,8843,8856,8865,8874,8876,8878,8885,8887,8893,8896,8905,8910,8955,8970,8971,8991,8995,9014,9016,9042,9043,9063,9069,9104,9106,9107,9116,9131,9157,9227,9359,9471]
B组
[12,16,29,32,33,35,39,42,44,44,44,45,45,45,45,45,45,45,45,45,47,51,51,51,57,57,60,61,61,62,71,75,75,75,75,75,75,76,76,76,76,76,76,79,84,84,85,89,93,93,95,96,97,98,100,100,100,100,100,102,102,103,105,108,109,109,109,109,109,109,109,109,109,109,109,109,110,110,112,113,114,114,116,116,118,119,120,121,122,124,125,128,129,130,131,132,133,133,137,138,144,144,146,146,146,148,149,149,150,150,150,151,153,155,157,159,164,164,164,167,169,170,171,171,171,171,173,174,175,176,176,177,178,179,180,181,181,183,184,185,187,191,193,199,203,203,205,205,206,212,213,214,214,219,224,224,224,225,225,226,227,227,228,231,234,234,235,237,240,244,245,245,246,246,246,248,249,250,250,251,255,255,257,264,264,267,270,271,271,281,282,286,286,291,291,292,292,294,295,299,301,302,304,304,304,304,304,306,308,314,318,329,340,344,345,356,359,363,368,368,371,375,379,386,389,390,392,394,408,418,438,440,456,456,458,460,461,467,491,503,505,508,524,557,558,568,591,609,622,656,665,668,687,705,728,817,839,965,1013,1093,1126,1512,1935,2159,2384,2424,2426,2484,2738,2746,2751,3006,3184,3184,3184,3184,3184,4023,5842,5842,6502,7443,7781,8132,8237,8501]
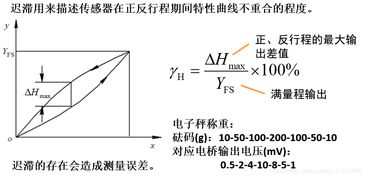
阵列统计:
A组B组
总数231 286
平均7534.71 575.56
标准差1595.04 1316.03
解决方案
我只是想用密度估计指出的另一种方法。
由于您的数据,很容易适应平滑 PDF使用的核密度估计。下面蟒蛇code展示了如何使用 SciPy的 KDE的模块。
从scipy.stats.kde进口gaussian_kde
从numpy的进口linspace
进口matplotlib.pyplot为PLT
数据1 = [385,515,975,1136,2394,2436,4051,4399,4484,4768,4768,4849,4856,4954,5020,5020,5020,5020,5020,5020,5020,5020,5020,5052,5163,5200,5271,5421,5421,5442,5746,5765,5903,5992,5992,6046,6122,6205,6208,6239,6310,6360,6416,6512,6536,6543,6581,6609,6696,6699,6752,6796,6806,6855,6859,6886,6906,6911,6923,6953,7016,7072,7086,7089,7110,7232,7278,7293,7304,7309,7348,7367,7378,7380,7419,7453,7454,7492,7506,7549,7563,7721,7723,7731,7745,7750,7751,7783,7791,7813,7813,7814,7818,7833,7863,7875,7886,7887,7902,7907,7935,7942,7942,7948,7973,7995,8002,8013,8013,8015,8024,8025,8030,8038,8041,8050,8056,8060,8064,8071,8081,8082,8085,8093,8124,8139,8142,8167,8179,8204,8214,8223,8225,8247,8248,8253,8258,8264,8265,8265,8269,8277,8278,8289,8300,8312,8314,8323,8328,8334,8363,8369,8390,8397,8399,8399,8401,8436,8442,8456,8457,8471,8474,8483,8503,8511,8516,8533,8560,8571,8575,8583,8592,8593,8626,8635,8635,8644,8659,8685,8695,8695,8702,8714,8715,8717,8729,8732,8740,8743,8750,8756,8772,8772,8778,8797,8828,8840,8840,8843,8856,8865,8874,8876,8878,8885,8887,8893,8896,8905,8910,8955,8970,8971,8991,8995,9014,9016,9042,9043,9063,9069,9104,9106,9107,9116,9131,9157,9227,9359,9471]
数据2 = [12,16,29,32,33,35,39,42,44,44,44,45,45,45,45,45,45,45,45,45,47,51,51,51,57,57,60,61,61,62,71,75,75,75,75,75,75,76,76,76,76,76,76,79,84,84,85,89,93,93,95,96,97,98,100,100,100,100,100,102,102,103,105,108,109,109,109,109,109,109,109,109,109,109,109,109,110,110,112,113,114,114,116,116,118,119,120,121,122,124,125,128,129,130,131,132,133,133,137,138,144,144,146,146,146,148,149,149,150,150,150,151,153,155,157,159,164,164,164,167,169,170,171,171,171,171,173,174,175,176,176,177,178,179,180,181,181,183,184,185,187,191,193,199,203,203,205,205,206,212,213,214,214,219,224,224,224,225,225,226,227,227,228,231,234,234,235,237,240,244,245,245,246,246,246,248,249,250,250,251,255,255,257,264,264,267,270,271,271,281,282,286,286,291,291,292,292,294,295,299,301,302,304,304,304,304,304,306,308,314,318,329,340,344,345,356,359,363,368,368,371,375,379,386,389,390,392,394,408,418,438,440,456,456,458,460,461,467,491,503,505,508,524,557,558,568,591,609,622,656,665,668,687,705,728,817,839,965,1013,1093,1126,1512,1935,2159,2384,2424,2426,2484,2738,2746,2751,3006,3184,3184,3184,3184,3184,4023,5842,5842,6502,7443,7781,8132,8237,8501]
PDF1 = gaussian_kde(数据1)
pdf2 = gaussian_kde(数据2)
X = linspace(0,9500,1000)
plt.plot(X,PDF1(x)中,'R')
plt.plot(X,pdf2(x)中,'G')
plt.legend(['DATA1 PDF格式,data2的PDF格式'])
plt.show()
在该图中,绿色是PDF格式用于第二数据集;红色是PDF格式为第一数据集。明确的决定边界是穿过其中的绿色相交带有红色的点的垂直线。
要数值上找到的边界,我们可以执行类似如下(假设只有一个交点,否则就没有意义了):
min_diff = 10000
min_diff_x = -1
对于x在linspace(3600,4000,400):
的diff = ABS(PDF1(X) - pdf2(X))
如果DIFF< min_diff:
min_diff =差异
min_diff_x = X
打印min_diff,min_diff_x
我们发现,该边界在3762位于约。
如果有两个PDF文件的多个交叉点,使$ P $什么类别的数据点 pdictions X 落入,我们计算 PDF1(X)和 pdf2(X),最大之一是尽量减少贝叶斯风险类。请参见这里的更多详细信息的贝叶斯风险评估的话题prediction错误的概率。
下面说明了包括实际上是三个PDF文件,随时查询点的例子 X ,我们应分别向三个PDF文件,并选择与 PDF(X)为predicted类。
I have two sets of data that overlap a bit (see plot below). I need to find the point between these sets where one would guess an unknown data point would belong in a particular category.
If I have a new data point (let's say 5000), and had to bet $$$ on whether it belongs in Group A or Group B, how can I calculate the point that makes my bet most sure?
See sample dataset and accompanying plot below with approximated point between these groups (calculated by eye).
GROUP A
[385,515,975,1136,2394,2436,4051,4399,4484,4768,4768,4849,4856,4954,5020,5020,5020,5020,5020,5020,5020,5020,5020,5052,5163,5200,5271,5421,5421,5442,5746,5765,5903,5992,5992,6046,6122,6205,6208,6239,6310,6360,6416,6512,6536,6543,6581,6609,6696,6699,6752,6796,6806,6855,6859,6886,6906,6911,6923,6953,7016,7072,7086,7089,7110,7232,7278,7293,7304,7309,7348,7367,7378,7380,7419,7453,7454,7492,7506,7549,7563,7721,7723,7731,7745,7750,7751,7783,7791,7813,7813,7814,7818,7833,7863,7875,7886,7887,7902,7907,7935,7942,7942,7948,7973,7995,8002,8013,8013,8015,8024,8025,8030,8038,8041,8050,8056,8060,8064,8071,8081,8082,8085,8093,8124,8139,8142,8167,8179,8204,8214,8223,8225,8247,8248,8253,8258,8264,8265,8265,8269,8277,8278,8289,8300,8312,8314,8323,8328,8334,8363,8369,8390,8397,8399,8399,8401,8436,8442,8456,8457,8471,8474,8483,8503,8511,8516,8533,8560,8571,8575,8583,8592,8593,8626,8635,8635,8644,8659,8685,8695,8695,8702,8714,8715,8717,8729,8732,8740,8743,8750,8756,8772,8772,8778,8797,8828,8840,8840,8843,8856,8865,8874,8876,8878,8885,8887,8893,8896,8905,8910,8955,8970,8971,8991,8995,9014,9016,9042,9043,9063,9069,9104,9106,9107,9116,9131,9157,9227,9359,9471]
GROUP B
[12,16,29,32,33,35,39,42,44,44,44,45,45,45,45,45,45,45,45,45,47,51,51,51,57,57,60,61,61,62,71,75,75,75,75,75,75,76,76,76,76,76,76,79,84,84,85,89,93,93,95,96,97,98,100,100,100,100,100,102,102,103,105,108,109,109,109,109,109,109,109,109,109,109,109,109,110,110,112,113,114,114,116,116,118,119,120,121,122,124,125,128,129,130,131,132,133,133,137,138,144,144,146,146,146,148,149,149,150,150,150,151,153,155,157,159,164,164,164,167,169,170,171,171,171,171,173,174,175,176,176,177,178,179,180,181,181,183,184,185,187,191,193,199,203,203,205,205,206,212,213,214,214,219,224,224,224,225,225,226,227,227,228,231,234,234,235,237,240,244,245,245,246,246,246,248,249,250,250,251,255,255,257,264,264,267,270,271,271,281,282,286,286,291,291,292,292,294,295,299,301,302,304,304,304,304,304,306,308,314,318,329,340,344,345,356,359,363,368,368,371,375,379,386,389,390,392,394,408,418,438,440,456,456,458,460,461,467,491,503,505,508,524,557,558,568,591,609,622,656,665,668,687,705,728,817,839,965,1013,1093,1126,1512,1935,2159,2384,2424,2426,2484,2738,2746,2751,3006,3184,3184,3184,3184,3184,4023,5842,5842,6502,7443,7781,8132,8237,8501]
Array Stats:
Group A Group B
Total Numbers 231 286
Mean 7534.71 575.56
Standard Deviation 1595.04 1316.03
解决方案
I just want to point out another approach using density estimation.
Given your data, it's easy to fit a smoothed pdf using kernel density estimation. The below python code shows how to use the kde module in scipy.
from scipy.stats.kde import gaussian_kde
from numpy import linspace
import matplotlib.pyplot as plt
data1 = [385,515,975,1136,2394,2436,4051,4399,4484,4768,4768,4849,4856,4954,5020,5020,5020,5020,5020,5020,5020,5020,5020,5052,5163,5200,5271,5421,5421,5442,5746,5765,5903,5992,5992,6046,6122,6205,6208,6239,6310,6360,6416,6512,6536,6543,6581,6609,6696,6699,6752,6796,6806,6855,6859,6886,6906,6911,6923,6953,7016,7072,7086,7089,7110,7232,7278,7293,7304,7309,7348,7367,7378,7380,7419,7453,7454,7492,7506,7549,7563,7721,7723,7731,7745,7750,7751,7783,7791,7813,7813,7814,7818,7833,7863,7875,7886,7887,7902,7907,7935,7942,7942,7948,7973,7995,8002,8013,8013,8015,8024,8025,8030,8038,8041,8050,8056,8060,8064,8071,8081,8082,8085,8093,8124,8139,8142,8167,8179,8204,8214,8223,8225,8247,8248,8253,8258,8264,8265,8265,8269,8277,8278,8289,8300,8312,8314,8323,8328,8334,8363,8369,8390,8397,8399,8399,8401,8436,8442,8456,8457,8471,8474,8483,8503,8511,8516,8533,8560,8571,8575,8583,8592,8593,8626,8635,8635,8644,8659,8685,8695,8695,8702,8714,8715,8717,8729,8732,8740,8743,8750,8756,8772,8772,8778,8797,8828,8840,8840,8843,8856,8865,8874,8876,8878,8885,8887,8893,8896,8905,8910,8955,8970,8971,8991,8995,9014,9016,9042,9043,9063,9069,9104,9106,9107,9116,9131,9157,9227,9359,9471]
data2 = [12,16,29,32,33,35,39,42,44,44,44,45,45,45,45,45,45,45,45,45,47,51,51,51,57,57,60,61,61,62,71,75,75,75,75,75,75,76,76,76,76,76,76,79,84,84,85,89,93,93,95,96,97,98,100,100,100,100,100,102,102,103,105,108,109,109,109,109,109,109,109,109,109,109,109,109,110,110,112,113,114,114,116,116,118,119,120,121,122,124,125,128,129,130,131,132,133,133,137,138,144,144,146,146,146,148,149,149,150,150,150,151,153,155,157,159,164,164,164,167,169,170,171,171,171,171,173,174,175,176,176,177,178,179,180,181,181,183,184,185,187,191,193,199,203,203,205,205,206,212,213,214,214,219,224,224,224,225,225,226,227,227,228,231,234,234,235,237,240,244,245,245,246,246,246,248,249,250,250,251,255,255,257,264,264,267,270,271,271,281,282,286,286,291,291,292,292,294,295,299,301,302,304,304,304,304,304,306,308,314,318,329,340,344,345,356,359,363,368,368,371,375,379,386,389,390,392,394,408,418,438,440,456,456,458,460,461,467,491,503,505,508,524,557,558,568,591,609,622,656,665,668,687,705,728,817,839,965,1013,1093,1126,1512,1935,2159,2384,2424,2426,2484,2738,2746,2751,3006,3184,3184,3184,3184,3184,4023,5842,5842,6502,7443,7781,8132,8237,8501]
pdf1 = gaussian_kde(data1)
pdf2 = gaussian_kde(data2)
x = linspace(0, 9500, 1000)
plt.plot(x, pdf1(x),'r')
plt.plot(x, pdf2(x),'g')
plt.legend(['data1 pdf', 'data2 pdf'])
plt.show()
In the graph, the green is the pdf for the second dataset; the red is the pdf for the first dataset. Clearly the decision boundary is the vertical line that passes through the point where the green intersects with the red.
To find the the boundary numerically, we can perform something like below (assume there is only one intersection, otherwise it does not make sense):
min_diff = 10000
min_diff_x = -1
for x in linspace(3600, 4000, 400):
diff = abs(pdf1(x) - pdf2(x))
if diff < min_diff:
min_diff = diff
min_diff_x = x
print min_diff, min_diff_x
We found out that the boundary is located approximately at 3762.
If there are multiple intersections of the two pdfs, to make predictions of what class a data point x falls into, we calculate pdf1(x) and pdf2(x), the max one is the class that minimize the bayes risk. See here for more details on the topic of Bayes risk and evaluation of the probability of prediction error.
Below illustrates an example that includes actually three pdfs, at any query point x, we should ask the three pdfs separately and pick the one with the maximum value of pdf(x) as the predicted class.








