哈希数组映射特里(HAMT)特里、数组、HAMT
我试图让我的头周围的 HAMT 的细节。我有用Java实现一个自己只是为了了解。我所熟悉的尝试次数,我觉得我得到了HAMT的主要概念。
基本上,
两种类型的节点:
键/值
键值节点:
K键
V值
首页
索引节点:
INT位图(32位)
节点[]表(最大长度为32)
生成的32位散列为对象。
通过散列5位的时间步骤。 (0-4,5-9,10-14,15-19,20-24,25-29,30-31)
注意:最后一步(7日)只有2位。
在每个步骤中,发现5位整数位图中的位置。例如整数== 5位== 00001
如果该位为1,则散列的那部分存在。
如果该位为0,则键不存在。
如果该键存在,通过计数在0和位置的位图中1的个数找到它的索引到表中。例如整数== 6位== 0101010101 ==指数3
如果该表指向一个键/值节点然后比较关键。
如果该表指向一个索引节点然后去2向前迈进了一步。
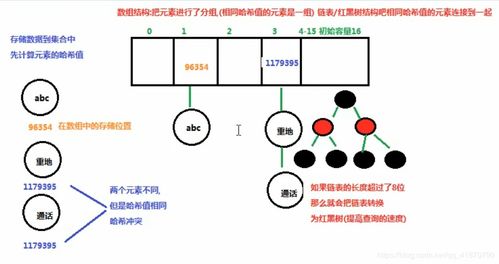
我不太明白的部分是碰撞检测和缓解。在链接的文章,他暗示了它:
现有密钥,然后在新的子哈希表和在插入 新增加的关键。散列的每次5更多的比特被用于在 碰撞的概率通过的1/32倍减少。偶尔 整个32位散列可以被消耗掉,一个新的必须计算 迪FF erentiate这两个键。
如果我要计算一个新的哈希并存储在那个新的哈希对象;你怎么会都无法查找对象的结构呢?当进行查询,是不是产生了初始散列,而不是重新计算哈希值。
我一定是失去了一些东西......
BTW:该HAMT执行得相当好,这是一个哈希地图和地图树在我的测试间位于
。 数据结构添加时间删除时间排序加入时间排序的删除时间查询时间大小
Java的哈希表38.67毫秒18毫秒30毫秒15毫秒16.33毫秒8.19 MB
HAMT 68.67毫秒30毫秒57.33毫秒35.33毫秒33毫秒10.18 MB
Java的树图86.33毫秒78毫秒75毫秒39.33毫秒76毫秒8.79 MB
Java的跳跃列表地图111.33毫秒106毫秒72毫秒41毫秒72.33毫秒9.19 MB
解决方案
有纸我想你可能错过的两部分。首先是位立即preceding你引用位:
或密钥将与现有的碰撞。在这种情况下,现有的键 必须更换一个子哈希表和现有密钥的下一个5位的哈希 计算。如果仍有一个碰撞则这个过程被重复,直到没有碰撞 发生。
所以,如果你在表对象A和添加对象B的冲突,在这钥匙发生冲突的细胞将是一个指向另一个子表(他们不冲突)。
接下来,挂纸的第3.7节描述了生成一个新的哈希方法,当你运行了你的第一个32位的末尾:
散列函数是针对给一个32位的哈希值。该算法需要 散列可以扩展到比特的任意数目。这是通过 老调重弹结合重$ P $的整数的关键psenting线索水平,零感 根。因此,如果两个键做给相同的初始哈希则老调重弹有 概率1 2 ^ 32进一步冲突。
如果这似乎并没有解释什么,说的和我将扩展这个答案更多的细节。
I am trying to get my head around the details of a HAMT. I'd have implemented one myself in Java just to understand. I am familiar with Tries and I think I get the main concept of the HAMT.
Basically,
Two types of nodes:
Key/Value
Key Value Node:
K key
V value
Index
Index Node:
int bitmap (32 bits)
Node[] table (max length of 32)
Generate a 32-bit hash for an object. Step through the hash 5-bits at a time.
(0-4, 5-9, 10-14, 15-19, 20-24, 25-29, 30-31)
note: the last step (7th) is only 2 bits.
At each step, find the position of that 5-bit integer in the bitmap. e.g. integer==5 bitmap==00001
If the bit is a 1 then that part of the hash exist.
If the bit is a 0 then key doesn't exist.
If the key exists, find it's index into the table by counting the number of 1s in the bitmap between 0 and the position. e.g. integer==6 bitmap==0101010101 index==3
The part I don't quite understand is collision detection and mitigation. In the linked paper he alludes to it:
The existing key is then inserted in the new sub-hash table and the new key added. Each time 5 more bits of the hash are used the probability of a collision reduces by a factor of 1/32. Occasionally an entire 32 bit hash may be consumed and a new one must be computed to differentiate the two keys.
If I were to compute a "new" hash and store the object at that new hash; how would you ever be able to look-up the object in the structure? When doing a look-up, wouldn't it generate the "initial" hash and not the "re-computed hash".
I must be missing something.....
BTW: The HAMT performs fairly well, it's sits between a hash map and tree map in my tests.
Data Structure Add time Remove time Sorted add time Sorted remove time Lookup time Size
Java's Hash Map 38.67 ms 18 ms 30 ms 15 ms 16.33 ms 8.19 MB
HAMT 68.67 ms 30 ms 57.33 ms 35.33 ms 33 ms 10.18 MB
Java's Tree Map 86.33 ms 78 ms 75 ms 39.33 ms 76 ms 8.79 MB
Java's Skip List Map 111.33 ms 106 ms 72 ms 41 ms 72.33 ms 9.19 MB
解决方案
There's two sections of the paper I think you might of missed. The first is the bit immediately preceding the bit you quoted:
Or the key will collide with an existing one. In which case the existing key must be replaced with a sub-hash table and the next 5 bit hash of the existing key computed. If there is still a collision then this process is repeated until no collision occurs.
So if you have object A in the table and you add object B which clashes, the cell at which their keys clashed will be a pointer to another subtable (where they don't clash).
Next, Section 3.7 of the paper you linked describes the method for generating a new hash when you run off the end of your first 32 bits:
The hash function was tailored to give a 32 bit hash. The algorithm requires that the hash can be extended to an arbitrary number of bits. This was accomplished by rehashing the key combined with an integer representing the trie level, zero being the root. Hence if two keys do give the same initial hash then the rehash has a probability of 1 in 2^32 of a further collision.
If this doesn't seem to explain anything, say and I'll extend this answer with more detail.








