从使用Python基于AJAX的网站提取信息网站、信息、Python、AJAX
我想检索基于Ajax等网站www.snapbird.org使用Python查询结果。因为它没有在网页源代码显示,我不知道如何着手。 我是一个Python新手,因此这将是巨大的,如果我能得到一个指向正确的方向前进。 我也开到一些其他的方法来工作,如果这是更容易
解决方案可能会使用类似浏览器的一个简单的解决方案机械化。所以,你可以浏览网站,跟踪链接,让搜索和几乎一切,你可以与用户界面的浏览器做的。
但是,对于一个非常sepcific工作,你可能甚至不需要这样的库,你可以使用的urllib 和的urllib2 Python库进行连接并读取响应...您可以使用萤火虫看到搜索和响应的数据结构体。然后使用的urllib 来使相关参数的请求......
通过一个示例...
我与 joyvalencia 搜索和检查请求的URL与萤火虫看到:
所以,调用这个URL以 urllib2.urlopen()将是同使得查询Snapbird。响应体是:
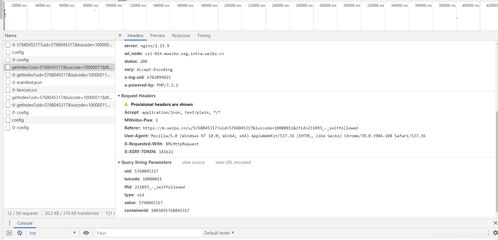
在使用的urlopen()和读取响应,上线就是你......然后,你可以使用 JSON 蟒蛇读取数据,并将其解析到一个Python的数据结构库...
I am trying to retrieve query results on sites based on ajax like www.snapbird.org using Python. Since it doesn't show in the page source, I am not sure how to proceed. I am a Python newbie and hence it would be great if I could get a pointer in the right direction. I am also open to some other approach to the task if that is easier
解决方案One easy solution might be using a browser like Mechanize. So you can browse site, follow links, make searches and nearly everything that you can do with a browser with user interface.
But for a very sepcific job, you may not even need a such library, you can use urllib and urllib2 python libraries to make a connection and read response... You can use Firebug to see data structure of a search and response body. Then use urllib to make a request with relevant parameters...
With an example...
I made a search with joyvalencia and check the request url with firebug to see:
http://api.twitter.com/1/statuses/user_timeline.json?screen_name=joyvalencia&count=100&page=2&include_rts=true&callback=twitterlib1321017083330
So calling this url with urllib2.urlopen() will be the same with making the query on Snapbird. Response body is:
twitterlib1321017083330([{"id_str":"131548107799396357","place":null,"geo":null,"in_reply_to_user_id_str":null,"coordinates":.......
When you use urlopen() and read the response, the upper string is what you get... Then you can use json library of python to read the data and parse it to a pythonic data structure...








