如何在PYTHON中读取、处理和写入大文件?大文件、如何在、PYTHON
2023-09-03 10:15:39
作者:哭着说再见
我有一个100 GB大小的txt文件。我必须以最快的方式读取它,做一些处理,并以与原始文件相同的顺序写入。对于读和写,我不能使用多处理,对于处理,我尝试了MAP但内存溢出,我也尝试了IMAP,但它似乎没有加快进程。
推荐答案
暂时忘掉加速问题吧,如果您必须处理一个100 GB的文件,您的问题应该是内存消耗。您的第一个问题是让它完全正常工作。
您不能将整个文件读入内存,然后对其进行处理(除非您恰好有100 GB的RAM)。您必须逐行阅读,或成批阅读,一次只处理部分内容。 因此,不使用file.read(),而使用file.readline()或file.read(some_size),具体取决于您读取文件。
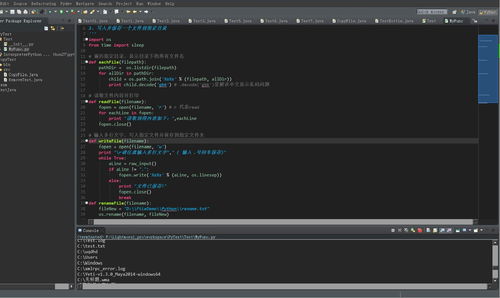
同样,如果您需要写入已处理的100 GB文件,请不要将所有结果收集在列表或其他文件中,在处理完原始文件的一行后立即将每行写入结果文件。
顺便说一句,我希望这是满足您的需求的最快的方法(相同的顺序),因为您可以忘记做任何不按顺序做的事情,然后进行排序。如果数据对于您的内存来说太大,您无法就地对其进行排序,虽然在文件系统上对其进行排序是可能的,但它更复杂,我有点怀疑这样会不会更快。
相关推荐
猜您喜欢

精彩图集







